

Zanim do zmiennych przejdziemy słów kilka o identyfikatorach, czyli o nazwach, które możemy nadawać różnych obiektom w PL/SQL. W przypadku tego ostatniego obiektami mogą być stałe, zmienne, kursory, wyzwalacze (triggers), procedury, funkcje, pakiety i zapewne jeszcze inne byty, o których nie mam w tym momencie większego pojęcia. Oczywiście w tym wpisie najbardziej interesują mnie – jak sam tytuł wskazuje – zmienne, ale zasady tworzenia identyfikatorów są identyczne bez względu do czego się one następnie odnoszą.
Główne założenia w tym zakresie wyglądają następująco:
- identyfikator musi zaczynać się od litery,
- maksymalna długość to 30 znaków,
- nie może zawierać białych znaków, czyli de facto spacji (co jest raczej dość oczywiste),
- ze znaków specjalnych można korzystać w dość ograniczonym zakresie, czyli do dyspozycji mamy znak dolara (‘$’), podkreślenie (‘_’) oraz hash (‘#’),
- w odróżnieniu od większości języków programowania wielkość liter nie ma żadnego znaczenia (w sumie jest to dość konsekwentne podejście w stosunku do SQL), czyli identyfikator “ZMIENNA” i “zmienna” odnosi się do tego samego obiektu,
- no i oczywiście w charakterze identyfikatorów nie możemy używać słów zarezerwowanych w rodzaju SELECT, BEGIN czy EXCEPTION..
Ten ostatni warunek można w pewnym sensie obejść poprzez użycie cudzysłowu, jak to zostało pokazane niżej, choć ponoć jest to uznawane za złą praktykę (moim zdaniem całkiem słusznie).
DECLARE
"end" VARCHAR2(15);
BEGIN
. . .
END;DOBRE PRAKTYKI TWORZENIA IDENTYFIKATORÓW
Skoro już o złych praktykach jesteśmy, to oczywiście oprócz formalnych wymogów, co do zasad tworzenia identyfikatorów, w każdym języku programowania występują pewne konwencje (dobre praktyki), do których warto się dostosować (albo chociaż rozumieć ich zastosowanie, co może być pomocne w przypadku inspekcji cudzego kodu), bo dzięki temu na ogół poprawia się czytelności kodu i tym samym łatwiejsze jest jego utrzymanie.
Przygotowując się do tego tekstu zapoznałem się z kilkoma takimi propozycjami dotyczącymi identyfikatorów w PL/SQL, ale żadna z nich – oprócz jednej – nie wydawała mi się specjalnie pomocna czy nawet sensowna (przynajmniej na tym etapie nauki, bo może po prostu nie widzę całego obrazka). Otóż wydaje mi się, że rzeczywiście dobrą praktyką w przypadku tworzenia identyfikatora jest użycie na początku jego nazwy litery lub dwóch, które od razu powiedzą do jakiego obiektu dana nazwa się odnosi. Na ten przykład dla obiektu zmienna byłaby to litera “v” (od “variable”), zaś kursorowi odpowiadałaby litera “c” (od “cursor” – co to za cudo będzie wyjaśnione w jednym z tekstów w przyszłości). Po tym wstępnym “samookreśleniu” pojawić się powienien znak podkreślenia, za którym dopiero dodajemy “właściwą” (czytaj: unikatową) nazwę, czyli na ten przykład mogłoby to być taka zmienna: v_name.
TYPY DANYCH
Drugim koniecznym elementem deklaracji zmiennych jest określenie typu danych, które mogą być do niej przypisane. Ponieważ jest to kurs dla hobbystów przyjmijmy dla uproszczenia, że do czynienia mamy wyłącznie z typami skalarnymi, czyli mówiąc po ludzku: z doskonale nam znanymi typami SQL w rodzaju varchar2 czy number. Wspomnieć w tym miejscu należy, że PL/SQL dodaje swoje własne typy i czasem nieco modyfikuje właściwości typów używanych w SQL, ale obecnie ma to dla nas drugorzędne znaczenie.
Określenie typu odbywa się w sposób, który wprawdzie został zaprezentowany wcześniej w tym tekście, ale dla porządku wywodu formalnie go zaprezentujemy. Jak widać niżej wystarczy po nazwie zmiennej podać rodzaj danych, które może nasza zmienna przechowywać:
DECLARE
v_imie VARCHAR2(15);
BEGIN
. . .
END;KOTWICZENIE TYPÓW
Oprócz “normalnego” przypisywania typów danych do zmiennych, w PL/SQL przewidziane został jeszcze inny mechanizm wykorzystywany w tym celu, który określany jest jako “kotwiczenie”. Polega on na czymś w rodzaju dziedziczenia typu danych powiązanego z jakimś innym obiektem bazodanowym, czyli na przykład z inną zmienną lub – co prawdopodobnie dużo częściej jest praktykowane – z konkretną kolumną dla danej tabeli.
DECLARE
v_name1 nazwa_tabeli.nazwa_kolumny%TYPE;
v_name2 v_name1%TYPE;
BEGIN
...
END;W przykładzie wyżej widzimy najpierw deklarację zmiennej v_name1, która odwołuje się do wybranej kolumny w konkretnej tabeli – najpierw podawana jest nazwa tabeli (w tym konkretnym przypadku zakładamy, że sięgamy do domyślnego schematu dla zalogowanego użytkownika, dlatego można było pominąć nazwę schematu), zaś później po kropce wskazana jest nazwa interesującej nas kolumny. Po tym wszystkim widzimy symbol “%” oraz słowo TYPE. W ten właśnie sposób wskazujemy, że nasza zmienna ma przejmować dokładnie taki sam typ wartości, co wskazana kolumna z wybranej tabeli. W przypadku zmiennej v_name2 nie odwołujemy się już wprost do tabeli, ale do wcześniej zadeklarowanej zmiennej v_name1.
PRZYPISANIE WARTOŚCI DO ZMIENNEJ
Jeśli chodzi o przypisanie wartości do zmiennej, to nie musimy tego robić od razu, czyli przy okazji jej deklaracji, natomiast jeśli tego nie zrobimy, to w większości wypadków PL/SQL przypisze do niech po prostu wartość null, a przynajmniej tak się dzieje w przypadku typów prostych … wróć … skalarnych.
Operatorem przypisania nie jest jednak znak równościm jak można byłoby się spodziewać wzorem innych języków programowania. Otóż przypisane owszem wymaga znaku równości, ale poprzedzonego dwukropkiem, czyli w takiej sytuacji zobaczymy coś takiego “:=”.
DECLARE
v_name VARCHAR2(50) := 'Borciugner';
BEGIN
dbms_output.put_line('Hello ' || v_name);
END;W przypadku wykonania powyższego kodu naszym oczom w “konsoli” wyświetlić się powinien napis Hello Borciugner.
| Użyta wyżej procedura put_line z pakietu dbms_output umożliwia wyświetlanie nam różnych wiadomości na ekranie. Co to jest procedura oraz pakiet, to z pewnością stanie się bardziej zrozumiałe pod koniec tego cyklu wpisów, na ten moment wystarczy informacja, że używa procedura udostępnia nam dość pożyteczny mechanizm, z którego nieraz jeszcze będziemy mieli okazję skorzystać. Niestety mam jednak poważny problem z tym, jak poprawnie powinienem jego działanie określić. Wyżej napisałem o “konsoli”, co pewnie miałoby więcej sensu w przypadku korzystania SQL*PLUS (co to za cudo to pewnie kiedyś o tym napiszę). Natomiast w przypadku SQL Developera jest po prostu specjalne okno, które nazywa się “Dbms Output” (widoczne niżej). Przy domyślnych ustawieniach SQL Devlopera jest ono chyba niedostępne, dlatego wcześniej należy po prostu wybrać opcję “Dbms Output” w menu View. |
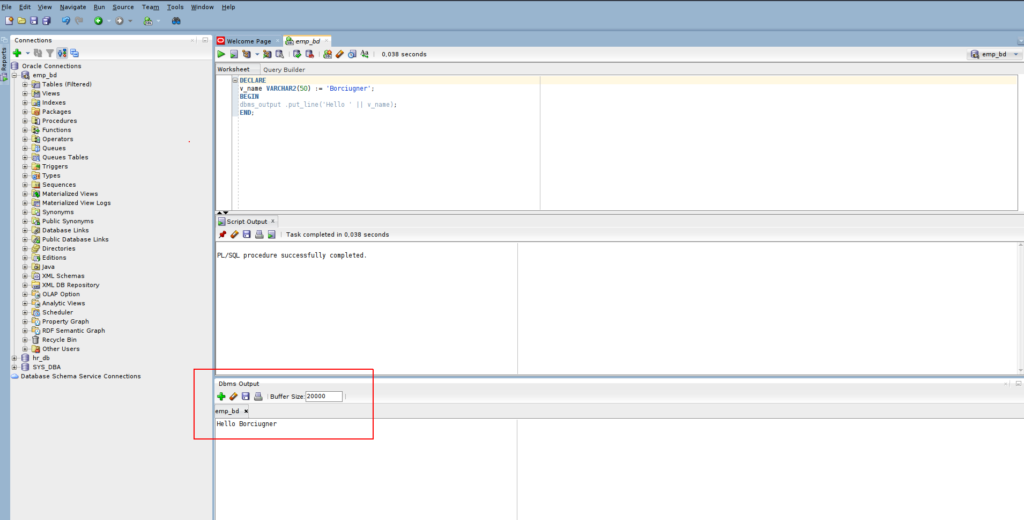
Coby nie było tak prosto, to w przypadku PL/SQL dwukropek nie jest jedynym “dziwactwem” w przypadku przypisywania wartości do zmiennej, ponieważ istnieje jeszcze inny, bardziej oryginalny sposób przypisywania wartości do zmiennych. Można bowiem w tym celu użyć słowa kluczowego DEFAULT.
DECLARE
v_name VARCHAR2(50) := 'Borciugner';
v_epitet v_name%TYPE DEFAULT 'WIELKI';
BEGIN
dbms_output.put_line(v_name ||' jest '||v_epitet);
END;ZASIĘG ZMIENNYCH
Jak już wspomniałem w poprzednim wpisie, program w PL/SQL może składać się z wielu bloków, ponieważ można je zagnieżdżać jedne w drugich. To oczywiście prowadzi wprost do zagadnienia zasięgu zmiennych, czyli kwestii ich widoczność w poszczególnych częściach programu. W przypadku PL/SQL sprawa wygląda dość prosto na pierwszy rzut oka, ponieważ można przyjąć, że zasięg zmiennej rozciąga się od momentu jej deklaracji do końca bloku, w którym ta zmienna została zadeklarowana. Tym samym obowiązuje tutaj pewna hierarchiczność, czyli zmienna zadeklarowana w bloku nadrzędnym (zewnętrznym), może być z powodzeniem używana we wszystkich blokach, które są podrzędne względem niej, ale już nie odwrotnie. Jakkolwiek to może brzmieć niespecjalnie zrozumiale, to wydaje mi się, że poniższy przykład powinien rozwiać wszelkie wątpliwości.
DECLARE --blok zewnętrzny start
v_zewn varchar2(40):='Zmienna zewnętrzna';
BEGIN
DBMS_OUTPUT.PUT_LINE(v_zewn);
DECLARE --blok wewnętrzny start
v_wewn varchar2(20):='Zmienna wewnętrzna';
BEGIN
DBMS_OUTPUT.PUT_LINE(v_wewn);
DBMS_OUTPUT.PUT_LINE(v_zewn);
v_zewn:='Zewnętrzna po zmianie';
END; --blok wewnętrzny koniec
DBMS_OUTPUT.PUT_LINE(v_zewn);
-- DBMS_OUTPUT.PUT_LINE(v_wewn);
END; --blok zewnętrzny koniecW wyniku działania tego kodu zobaczylibyśmy następujący rezultat:
Zmienna zewnętrzna
Zmienna wewnętrzna
Zmienna zewnętrzna
Zewnętrzna po zmianie
Jednak gdybyśmy spróbowali w bloku zewnętrznym odwołać się do zmiennej v_wewn, czyli usunęli znak komentarza w przedostatnim wierszu, wówczas zamiast ładnej listy pięciu łańcuchów znakowych, naszym oczom wyświetlałby się odpowiedni komunikat błędu.
TWORZENIE STAŁYCH
Już na sam koniec słowo o stałych w PL/SQL. By z nich skorzystać wystarczy po nazwie identyfikatora dodać słowo kluczowe CONSTANT, a potem już lecimy tak samo jak w przypadku zmiennych, z tą różnicą, że w momencie deklaracji musimy od razyu przypisać do niej jakąś wartość, ponieważ w przeciwnym razie ryzykujemy błędem.
Poniżej przykład użycia stałem w programie do wyliczania obwodu koła:
DECLARE
v_liczba_pi CONSTANT NUMBER := 3.14;
v_promien_kola NUMBER;
v_obwod_kola NUMBER;
BEGIN
v_promien_kola := 2;
v_obwod_kola := v_liczba_pi * v_promien_kola;
DBMS_OUTPUT.PUT_LINE(v_obwod_kola);
END;


